Tokens: What You Need to Know
GPT-3 uses tokens under the hood#
When you interact with GPT-3 it feels like this:

But under the hood it's really this:
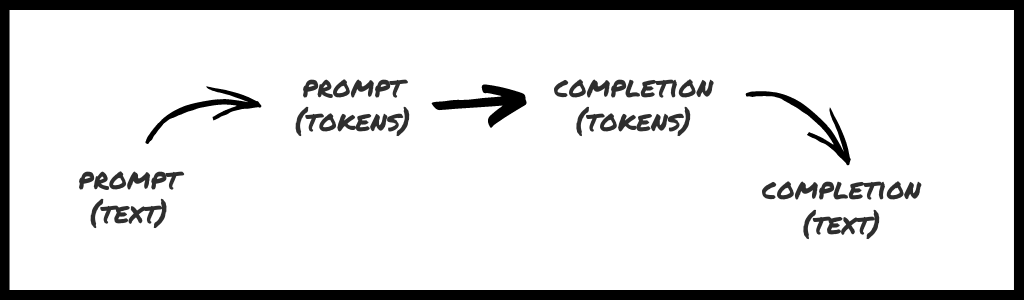
GPT-3 uses tokens (not paragraphs of text) under the hood. OpenAI is doing the work of converting to and from tokens for us. That's why we we're charged by tokens, have parameters like max_tokens, etc.
GPT-3 thinks in tokens#
GPT-3 was "trained" by feeding it lots of text. The training consisted of giving it lots of examples of text (a wikipedia entry, a news article, a blog post) while it worked to make sense of them. But there are good and bad ways to feed that text to a neural network like GPT-3. "Tokens" are the basic unit of meaning that GPT-3 is "thinking" about. When it's being trained it's forming associations between those "tokens." But how do we break the paragraphs of text into tokens?
Tokenization 101#
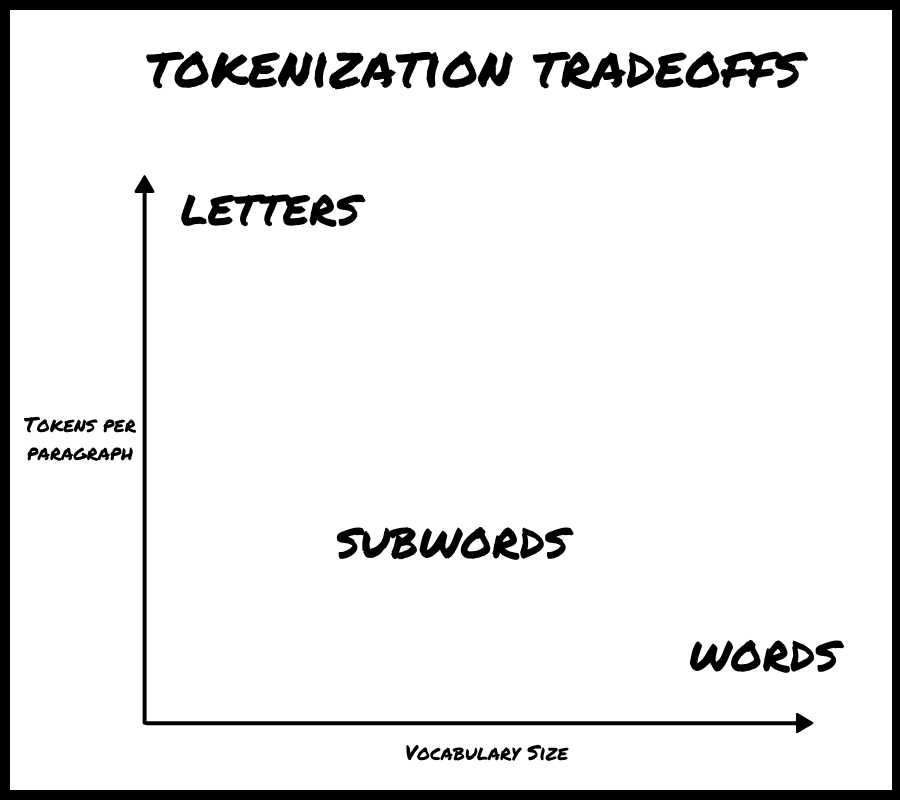
A first thought might be using words as tokens, but that has a couple of drawbacks. First, there are a lot of words (especially in English)! A neural network struggles as you increase the size of its vocabulary (the number of tokens). But using words is also inelegant. We can sometimes figure out part of what a word means even if we don't know what the whole word means. If you know what "any" and "place" mean, then you can probably figure out what "anyplace" means as well. These word fragments contain meaning.
Using letters isn't great either. It has one big advantage: you only need 26 tokens (in English), so we would have an extremely small vocabulary. But that has some big drawbacks. Because GPT-3 thinks in tokens, and because a word has many letters, if you switch from words to letters you increase the number of things GPT-3 has to keep in its (metaphorical) head to do the same work. For each paragraph of text we'll need many more tokens.
We need something between words and letters: subwords. Shorter words (e.g. and, but) just become tokens, but longer ones might be broken up into multiple tokens (e.g. unfortunately -> un + for + tun + ate + ly ). This keeps the best of both worlds.
This applies to more than GPT-3#
It's worth noting that "tokenization" isn't unique to GPT-3. Tokenization is a standard part of modern Natural Language Processing (NLP), the subfield of machine learning of which GPT-3 is a part.
NLP is a broad field and different tokenization methods are better for different use cases.
Okay, but how do you decide which words get to be their own token?#
GPT-2 and GPT-3 actually share the same tokenization method. They use a byte pair encoding (BPE) algorithm.
Can I see how words will be tokenized?#
Yes! If you want to get the answer from GPT-3 itself, you can!
Just do this:
const axios = require("axios");
const gpt = async () => { const temperature = 0.8; const data = { prompt: "I'm no stranger to", temperature, // The prompt will be returned with the response. echo: true, // Generate 0 new tokens. max_tokens: 0, // Returns the tokens (output and also input because of echo) with the logprobs. logprobs: 1, }; const result = await axios({ method: "post", // Might as well use ada as it's the cheapest. url: "https://api.openai.com/v1/engines/ada/completions", data, headers: { Authorization: "Bearer <your-token>", }, }); const tokenList = result.data.choices[0].logprobs.tokens; console.log(tokenList);};
(async () => { await gpt();})();You'll see a result like this:
["I", "'m", " no", " stranger", " to"];So "I'm" is being broken up into two tokens, but otherwise it's 1:1.
Token estimation
OpenAI provides us with a couple of rules of thumb on the pricing page.
As a point of reference, the collected works of Shakespeare are ~900,000 words or 1.2M tokens.
For regular English text, 1 token is approximately 4 characters.
These have worked okay for me, but your results my vary depending on language and the type of text you're using.
Conclusion
I hope you've found this helpful. If you have any other questions about tokens or GPT-3 leave a comment and I'll try to help.
If you want to read more about tokenizers, then check out Tokenizers: How machines read.