Using GPT-2 to generate Chiptune Music
I trained GPT-2 on the NES-MDB dataset (after converting MIDI -> ABC -> minABC) with a custom BPE tokenizer.
Remarkable parts:#
- I developed a simple method of reducing ABC size without removing musical quality (result is called minABC henceforth).
- I created a BPE tokenization schema that works well for minABC (at least the ABC files from NES-MDB), reducing the number of tokens required to represent a song by 6x.
- I modified the GPT-2 source so that you can integrate your own BPE tokenization configuration (instead of being forced to use theirs).
Unfortunately, I didn't get what I wanted in the end. In ~250 samples basically all of them plagiarized large sections of the training data. I think this was due to my small training corpus. Woops. I decided to finish my writeup anyway because it might help others.
Background#
Chris Donahue created NES-MDB, a dataset of music used on the Nintendo Entertainment System (NES). He then used it with a Transformer-XL architecture to create LakhNES, a deep neural network capable of generating chiptune music.
Gwern created music (folk, then other kinds) using a different approach: tuning the 117M GPT-2 language model on folk music in ABC notation. He started with existing ABC songs which were small enough to easily fit within the (default) 1024 GPT-2 token context window. The results were excellent, but the number of songs available in ABC were limited, so he began converting MIDI songs to ABC in order to access the much larger MIDI dataset. These converted ABC songs were much larger and wouldn't ordinarily fit in the GPT-2 context window. He got around this by throwing more money at the problem: scaling GPT-2 across many machines. The results of his second experiment were mixed creating mostly poor samples but some great ones.
Purpose#
I wanted to use Gwern's method (tuning GPT-2) to create chiptune music. Specifically, I suspected that:
- Chiptune music would convert well to ABC
- There was room to improve the MIDI -> ABC conversion that Gwern used (to allow entire songs to fit within the 1024 token context window)
- The songs created after training would be comparable or superior to the results from Chris's Transformer-XL approach.
Cleaning the data#
You can reference this Colab.
I noticed that many of the MIDI files provided were quite short. Out of the 5277 total, 460 were less than 3 seconds and 1764 were less than 10. I kept those between 10 seconds and 3 minutes in length (51 were longer than 3 minutes).
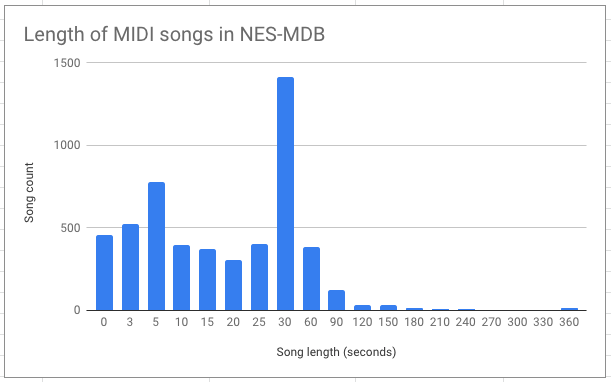
Many of the tracks under 10 seconds were more sounds than songs such as the many "Game Over" sounds.
Generally, tracks in the 10-30 second range seemed like songs and were meant to be looped.
I discarded tracks over 3 minutes because it was a small subset, I knew I needed to fit in the token window, and I didn't want to generate huge songs anyway.
Reducing ABC size#
You can reference this Colab.
Gwern knew reducing the size of the ABC files was important and took a few steps in that direction:
- Reducing the number of new lines via the
-bpl 99999flag (when running [midi2abc]((http://abc.sourceforge.net/abcMIDI/) - Removing spaces between notes (There for readability, not required by spec) after conversion
- Removing comments, error messages, and non-musical data after conversion
I took a few more steps:
- Removing empty voices
- Removing bars
- Removing title and ID
These changes reduced the average file size from 3083 to 2660 bytes. Not very exciting. You can read about my thought process and see a more detailed breakdown here.
Custom BPE Tokenization#
You can reference this Colab.
You can read more about tokenization here, but the idea is to break up text into pieces that have some semantic meaning. The default GPT-2 BPE process works well for English text but it was never meant to be used on ABC songs. That's why when benchmarking I used bytes as an approximation for the GPT-2 tokenizer.
But maybe we'll get lucky.
GPT-2 Tokenization of ABC songs#
Reference 002_1943_TheBattleofMidway_00_01Title.abc:
abc = """M:4/4L:1/8Q:1/4=120K:DV:1%%MIDI program 80=C2-C/2C/2c3/2z/2BA/2G3/2-G3/2E3/2z2=FF/2d3/2-d3/2=cz/2[BA-]/2A2-A/2z/2B3/2G3/2A/2zA/2G/2A/2z/2B/2zB/2A/2B/2d/2z=c3z/2c/2B/2c/2=FF/2=f3/2e3/2d3/2z/2=c3-=c3-V:2%%clef treble%%MIDI program 81z3/2G,3E,3/2z/2C,3/2-=C,4-C,/2-[=F,-C,]/2F,2-F,/2z/2G,3=C3/2=F3/2G3/2z/2E3/2=F/2zF3/2G/2zG3/2z/2^G3/2A3/2E3/2=C3/2D3/2z/2=c3/2B3/2A3/2G3-G/2-G3V:3%%clef treble%%MIDI program 38=Cz/2G,z/2CzG,z/2Cz/2G,z/2=Cz/2G,zCz/2=F,z/2=Cz/2=F,z/2A,zF,z/2B,z/2G,z/2=F,z/2F,z/2E,zE,z/2B,z/2=Cz/2Dz/2G,zD,z/2=F,z/2G,z/2B,z/2=CzC/2C/2C/2=Cz2A,/2z/2A,/2z2A,/2A,/2z/2z3/2A,/2>A,/2(3A,A,A,[A,A,]/2z/2A,/2z2A,/2A,/2z2A,/2z/2A,/2z2z/2z/2z/2z/2z/2z/2A,/2z/2A,/2V:4%%MIDI channel 10C,,,,/2z/2C,,,,/2z3/2C,,,,/2z/2C,,,,/2z2C,,,,/2>C,,,,/2C,,,,/2C,,,,/2z/2z/2C,,,,/2z/2C,,,,/2zz/2z/2C,,,,/2C,,,,/2z2C,,,,/2z/2C,,,,/2z3/2C,,,,/2z/2C,,,,/2C,,,,/2<C,,,,/2z/2z/2C,,,,/2C,,,,/2z/2zz/2C,,,,/2z/2C,,,,/2[C,,,,C,,,,]/2z/2z/2z/2C,,,,/2C,,,,/2zz/2z/2C,,,,/2>C,,,,/2C,,,,/2C,,,,/2z/2z/2C,,,,/2z/2C,,,,/2zz/2z/2C,,,,/2>C,,,,/2C,,,,/2C,,,,/2z/2z/2C,,,,/2z/2C,,,,/2zz/2z/2C,,,,/2>C,,,,/2C,,,,/2<C,,,,/2z/2z/2C,,,,/2z/2C,,,,/2zz/2C,,,,/2z/2C,,,,/2z2C,,,,/2C,,,,/2z/2z3/2C,,,,/2z/2C,,,,/2[C,,,,C,,,,]/2z/2C,,,,/2C,,,,/2<C,,,,/2C,,,,/2zz/2z/2C,,,,/2z/2C,,,,/2z3/2C,,,,/2z/2C,,,,/2z2z/2z/2z/2z/2z/2z/2C,,,,/2z/2"""
from transformers import GPT2Tokenizertokenizer = GPT2Tokenizer.from_pretrained("gpt2")encoding = tokenizer.encode(abc)token_count = len(encoding.tokens)print(token_count)That song is 1320 bytes and the GPT-2 tokenizer renders it as 1059 tokens. So it's a little better than bytes.
Our own tokenizer#
from tokenizers import Tokenizerfrom tokenizers.models import BPE
tokenizer = Tokenizer(BPE())from tokenizers.trainers import BpeTrainer
# More belowfrom tokenizers.pre_tokenizers import WhitespaceSplit
trainer = BpeTrainer(special_tokens=["<|endoftext|>"])
files = glob.glob('../nesabc/minified/*.abc')tokenizer.pre_tokenizer = WhitespaceSplit()tokenizer.train(files=files, trainer=trainer)encoding = tokenizer.encode(abc)token_count = len(encoding.tokens)print(token_count)Our tokenizer, trained on our ABC files, renders the same song as 154 tokens!
Pre-tokenization#
You have to specify a pre-tokenizer or else you can't save (and then reload) the tokenization config. See this issue.
I tried all the pre-tokenizers and compared the # tokens generated for the above text:
| Pre-tokenizer | Tokens generated |
|---|---|
| BertPreTokenizer | 4901 |
| ByteLevel | 5089 |
| Digits | 3453 |
| Metaspace | 1090 |
| Punctuation | 4907 |
| UnicodeScripts | 3086 |
| Whitespace | 3948 |
| WhitespaceSplit | 1048 |
| None | 1069 |
You can see there's a lot of variance.
How it's broken up#
You can also inspect how that song was tokenized:
print(encoding.tokens)
[ 'M:4/4\n', 'L:1/8\n', 'Q:1/4=120\n', 'K:D\n', 'V:1\n', '%%MIDI program 80\n', '=C2-', 'C/2C/2', 'c3/2z/2', 'BA/2', 'G3/2-G3/2', 'E3/2z2', ... 'C,,,,/2z/2C,,,,', '/2z2z', '/2z/2z/2z/2z/2z/2', 'C,,,,/2z/2']Pretty cool!
The tokenization training identified some common patterns in the music to save space.
E.g. E3/2z2 is a token. In ABC that means "play an E for 3/2 beats and then rest for 2."
And what about the rest of our dataset?#
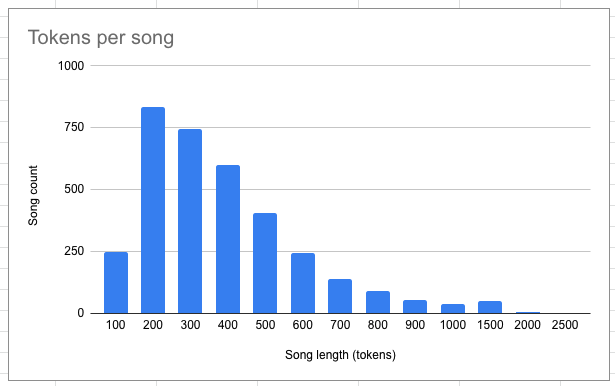
3405 of our 3463 songs are under 1K tokens!
That works for me. I decided not to remove the larger songs in the hopes that they would sort of balance out the very short ones.
Using our custom tokenizer with GPT-2#
This wasn't as straightforward as I'd hoped. Originally, I was hoping I could just replace the vocab.bpe and encoder.json files in the models folder, but that seems to be a legacy schema.
Still, it's not that bad. I just had to modify the encoder code in the gpt-2 repo. In doing so I ripped out some caching that probably makes things less efficient. You might want to look at or You can reference the last two commits of the modified repo to see what I changed or just take a look at the colab demonstrating use.
There's nothing particular to my tokenizer there. Just create your own using the huggingface tokenization package however you want and load it in.
Training#
You can reference this Colab.
It stopped improving after around 74k training steps to ~.12 loss.
I switched between 1, 2, and 3 batch sizes and also switched to Colab Pro partway through, so you may get different results.
Results#
Plagiarism#
I generated 100 samples, which translated to about 250 complete songs.
Unfortunately, most of the songs were highly plagiarized.
To detect plagiarism I took every 30 characters of my songs and tried to find an exact match of those 30 characters in the training data. This is probably too generous.
Out of 254 songs, 234 failed that test.
Many of those 234 were entire copies.
There are a couple of things I could have done differently to avoid this:
I think I screwed myself by only training on my pruned NES-MDB dataset. I should have started with a larger corpus and then fine-tuned on NES-MDB (that's what Chris did).
I also should have split the dataset into a validation and training set. The gpt-2 code allows for that although it isn't the default (and I didn't realize it was possible until after).
Nonsense#
The 20 that were left... they had what I'll charitably call chaotic energy.
The tricky part about multi-voice ABC files is that you have (in the example of NES songs) 4 tracks going simultaneously. Each track is separated like:
V:1<all voice 1 notes>V:2<all voice 2 notes>...As a result I think it's difficult for GPT-2 to associate everything properly. Voice 1 note 1 has to go well with voice 1 note 2, but it also has to go well with voice 2 note 1 and voice 3 note 1. And those won't even be the same character offsets.
Maybe we're asking too much of GPT-2 here?
You can download the final ABC files here.
I've embeded a few of the less plagiarized songs below.
Next steps#
I could train GPT-2 on the minABC version of the Lakh dataset first and then on NES-MDB.
I could use the same Transformer architecture that Chris did but just use minABC instead (also pretrained on Lakh).
I'm not sure that I'm gaining anything by using GPT-2 here. I'm basically throwing out the existing model because ABC songs are so different from English text. I'm thinking I'll start with Transformer-XL.